Freelancer Data Scientist | Researcher | Consultant

Projects Completed: 1731
Ratings: ★★★★★ 4.9/5
A Sample of Data Science ProjectI am Sean, an experienced Freelancer data scientist, researcher, and data consultant. For the last six years, I have helped businesses, researchers, and entrepreneurs make informed decisions by offering insights from data.
Whether you are a researcher, business person, or entrepreneur, I will help you understand the industry trends, answer your hypothesis, make prediction models for your business, cluster your data, and make meaning.
Whether you need a data-driven solution or want to explore the world of data science, I am here to make it happen. Let us connect and turn your data into actionable insights.
Freelance Data Science Project: Machine Learning Sample Project
Case study: As a freelancer data scientist, a client has approached you and needs help in predicting the solubility of molecules in water or other solvents. The solubility prediction model will help the client with drug discovery and development.
The client has presented you with data on different molecules and their solubility to use for developing the machine learning model.
It is up to you as a freelancer data scientist to decide the type of models to use and how to test the results.
A Sample Solution of the data science Project using Python
First, we will start by loading the given data in Python. In this loading, we will use pandas, a Python library for data manipulation. Below is the code for loading the data and a snippet of the data frame.
CodePreview of the Loaded Data
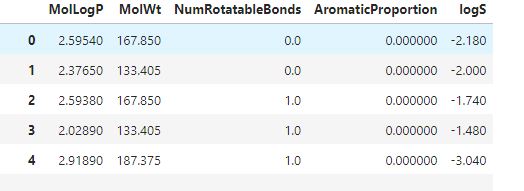
As you can see from the picture, the data has five columns. Logs which are in the last column the solubility of the molecules after they were dissolved in water and the results recorded. For the MOLlogP, it represents the logarithm of the partition coefficient of the molecules.
MolWt represents the molecular weight of the molecules while the NumRotatableBonds present the number of rotatable bonds in the molecule and finally, Aromaticproportion presents the number of aromatic bonds present in the molecules.
The interest in this freelance data science project is to evaluate if these given data can be used to predict the solubility of the molecules.
Data Preprocess, Preparation, and Separation
To start developing the models, we need to preprocess the data and separate it into two groups say X and Y. X will be the independent variables (MOLlogP, MolWt, NumRotatableBonds, Aromaticproportion). These are the variables that will be used as predictors of the Y variable. The Y variable is the solubility column which is LogS.
CodeY = df [“LogS”]X = df [[ “MOLlogP, MolWt, NumRotatableBonds, Aromaticproportion”]] The Data Splitting Process
Now that we have separated the data into X and Y, where X are the predictors (independent variables) and Y is the predicted (dependent variable), we need to split the data into two segments, the one we will use for training the model, and the one for testing the accuracy of the model.
The overall data has 1114 rows. We need to use 80% of these rows in training the models and 20% of these rows in testing the model. Therefore, the split will be done on the ratio of 8:2.
This will result in having 915 rows for the training set and 229 rows for the testing set as shown in the below pictures.
CodeX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)As you can note from the code, we have put the test_size to 0.2 which is 20%. The random_state makes the data splitting remain the same anytime we run the code.
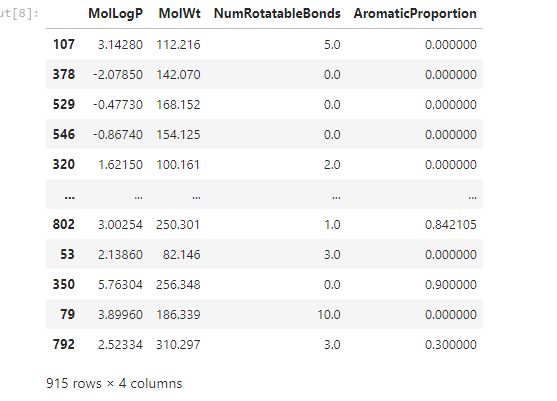
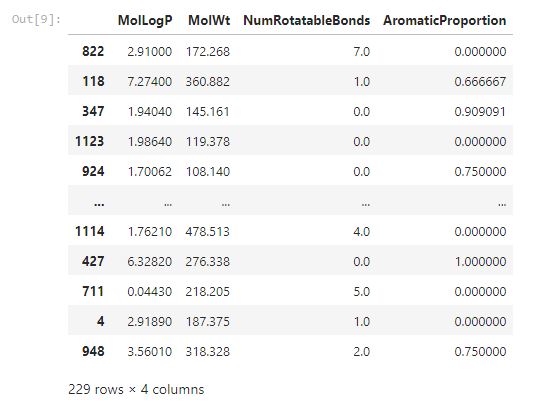
The first picture shows data with 915 rows and 4 columns. That is 80% of the data we are using for model training. The other one shows data with 229 rows and 4 columns. That is the data for testing which is 20% of the total rows. The rows are four because we dropped the dependent one LogS.
Building Linear Regression and Random Forest Models
Linear Regression
To build the linear regression model, you will need to use the Sklearn library. Using this library, you will import LinearRegression.
Codefrom Sklearn.linear_model import LinearRegressionlr = LinearRegression ()lr.fit (x_train, y_train) We have developed the model and trained it using the train data which accounts for 80% of the rows. Next, we develop and train the random forest model.
Codefrom sklearn.ensemble import RandomForestRegressorrf = RandomForestRegressor(max_depth=2, random_state=100)rf.fit(X_train, y_train)Using the Two Models to Make Predictions for the Solubility of the Molecules
Making predictions using the Linear Model
Codey_lr_train_pred = lr.predict(X_train)y_lr_test_pred = lr.predict(X_test)Making predictions using the Random Forest Model
Codey_rf_train_pred = rf.predict(X_train)y_rf_test_pred = rf.predict(X_test)If you print any of the codes above, you will get the prediction summary of the models.
Evaluating the Performance of the Random Forest Model and the Linear Regression Model
Linear Model Evaluation Code
Codefrom sklearn.metrics import mean_squared_error, r2_scorelr_train_mse = mean_squared_error(y_train, y_lr_train_pred)lr_train_r2 = r2_score(y_train, y_lr_train_pred)lr_test_mse = mean_squared_error(y_test, y_lr_test_pred)lr_test_r2 = r2_score(y_test, y_lr_test_pred)Random Forest Model Evaluation Code
Codefrom sklearn.metrics import mean_squared_error, r2_scorerf_train_mse = mean_squared_error(y_train, y_rf_train_pred)rf_train_r2 = r2_score(y_train, y_rf_train_pred)rf_test_mse = mean_squared_error(y_test, y_rf_test_pred)rf_test_r2 = r2_score(y_test, y_rf_test_pred)Combining the Two Models Results to Return as One
Codedf_models = pd.concat([lr_results, rf_results], axis=0)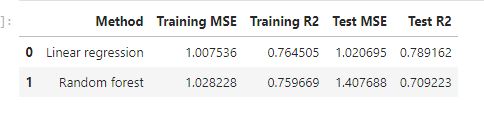
Visualizing the Prediction Data to Evaluate the Models Further
Codeimport matplotlib.pyplot as pltimport numpy as npplt.figure(figsize=(5,5))plt.scatter(x=y_train, y=y_lr_train_pred, c="#7CAE00" ,alpha=0.3)z = np.polyfit(y_train, y_lr_train_pred, 1)p = np.poly1d(z)plt.plot(y_train, p(y_train), '#F8766D')plt.ylabel('Predict LogS')plt.xlabel('Experimental LogS')Scatter Plot
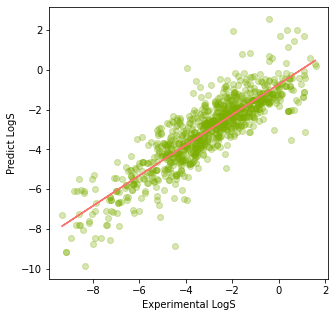
Analyzing the Evaluation Results and Making Recommendations
Linear Regression Model: This model shows relatively good performance. The R-squared of 0.764 on the training data and 0.789 on the testing data are close indicating that model I not overfitting. As such it makes it more reliable in generalizing the solubility of the molecules without significant overfitting.
Random Forest Model: This model also performs relatively well. The R-squared result on the training data is 0.760. comparatively, the R-squared on the predicted data of 0.709 indicates that the model performance on unforeseen data is slightly lower than the Linear Regression model. Also, an MSE of 1.028 indicates that the model is overfitting.
Conclusion and Recommendation
First, based on the scatter plot which is plotted with the Experimental LogS (X) and the Predicted LogS (Y) it shows a linear relationship indicating the independent variables can be used to predict the solubility of the molecules.
The linear regression model seems to perform better than the Random Forest Model which is overfitting therefore, the Linear Regression model should be used for predicting the solubility of the molecules
How to Hire Freelancer Data Scientist Online: Best Practices
The demand for freelancer data scientists is increasing due to increasing data across all industries. Data science freelancers have been rated as some of the in-demand professionals in the current tech space.
The capitalization of industries on data depends on the hiring of scarce freelancer data scientists. As such, managers are faced with the challenge of identifying the best talent to hire. The process of hiring freelance data scientists is not straightforward. However, the most important first step is to understand what the freelancer data scientists do in business. With this understanding, the process of hiring one online will be easy.
5 Ways to Find the Best Freelance Data Scientists Physically and Online
- Hiring Talent from Universities: Some universities teach the skills needed by freelancer data scientists, freelancer stata experts, and freelance data analysis consultants. Some of these universities include; Stanford, MIT, Berkley, Harvard, and Michigan. You can reach out directly to these universities and request to be connected with exceptional talent.
- Through Scanning the Membership of Online Groups Dedicated to Data Science: Many data scientists’ freelancers join groups dedicated to data science. They join these groups to share their journey and insights and also get insights from other experts. If you want to hire a freelance data scientist, you can start with groups like The R User Group and Python Interest groups.
- LinkedIn: LinkedIn is an open social platform that connects prospective employers with employees. If you want to opt for data science consultants freelance, you can scan through this platform and evaluate different profiles then select the ones that suit your needs
- Attending Workshops, Seminars, and Conferences: You can connect with freelance data manipulation experts in different conferences like structured Data conferences and Hadoop World conferences. These conferences are held in Boston, New York, Washington, London, and Singapore.
- Hosting Competitions: You can also host competitions to get connected with freelancer data scientists. Some of the places you can host these competitions include; Kaggle and Top Coder.
Most Needed Skills to Consider when Hiring Freelance Data Scientist
The skills needed to make a data science freelancer competent can be categorized into technical and non-technical skills.
Technical Skills
- Statistical analysis and computation skills
- Machine learning and deep learning skills
- Processing of large data sets and structuring them
- Data visualization, wrangling, mathematics, and programming
- Big data skills
Soft Skills
- Strong Communication skills
- Analytical mindset
- Problem-solving skills
- Time management
- Collaboration and teamwork
How to Structure Your Freelance Data Science Project for the Expert?
To ensure that our freelancer data scientists understand your project needs, there is a verifiable structure that you can use. In this section, we analyze this process.
- State Problem and Objectives: To ensure that the freelancer data scientist understands your project, you need to state the problem and the objectives you need to meet. You can also discuss this with the expert.
- The Data Source: Share with the expert the data source so that you can analyze it with him and evaluate the volume, complexity, and availability of the data.
- The timeline of the project: Ensure that you indicate the timeline of the project and the deliverables. You should also discuss this with the freelancer data scientist so that he can keep updating you periodically.
Frequently Asked Questions by Clients Concerning Freelance Data Science Services
- Do your freelancer data scientists have coding Skills? Yes, all our experts have vast skills in coding using languages like Python, Hadoop, R-statistics, stata, and many more. They use these skills in the development of machine learning models and other predictive models.
- Do your Freelance data analysis and data science consultants have degrees? All our experts who offer data science consultation freelance services have verified degrees, masters, and Ph. D.s from reputable schools like Michigan, MIT, Stanford, and others.
- How long does it take to complete my data science project? To complete freelance data science projects, there are many factors our freelancer data scientists consider. The scope of the project, volume of the data to be used, complexity, and the details of the report are some of the factors. However, you will discuss with our experts on the deadline and they will deliver.
- How are the payments for the projects on your site? Our payment process and cost are open. You will discuss with the expert about the cost and agree. We don’t have fixed prices and you are open to say your budget and agree with the freelancer data scientist amicably.
- Can I get a Refund if my Demands are not met? Our experts strive to ensure that all your project needs are met. However, in a situation where the freelancer data scientist doesn’t meet your demands, the company will make a full refund. This process can take around 48 hours but you must get your refund.
The AfroResearch Inc. Freelancer Data Scientists Services
AfroResearch Inc. is an online data analytics and data science platform that connects prospective clients with experienced USA-based freelancer data scientists, data analysts, researchers, and data consultants to help them with projects.
You only need to Live Chat the support team and get connected with an expert who you will discuss your project with. You will agree on the cost, timeline, and other details of the project.
The expert will guide you through the process of placing your order on the site and show you how to monitor it.